For the Last Time: Git Stores Snapshots Not Diffs
I have this discussion every month or two, so it’s finally time to write a blog post I can point people to instead. Git stores a snapshot of the entire file, not a diff
This is an understandable point of confusion, because most output from Git is in the form of diffs. Additionally, many other SCMs store changes as diffs instead of snapshots. However, Git stores an entire snapshot of each modified file.
If you want to see an explanation from someone much smarter than me, check out this video.
Illustrating Snapshots
The easiest way to show how Git stores snapshots is create a project and show the relative sizes of the .git object folder.
I’ve created a sample project on GitHub that contains two commits. The first commit introduces the text of Alice’s Adventures in Wonderland. The second commit makes a small modification to the text.
If you clone the repository and unpack the individual objects, you’ll see something like the following when you inspect the .git directory with WinDirStat.
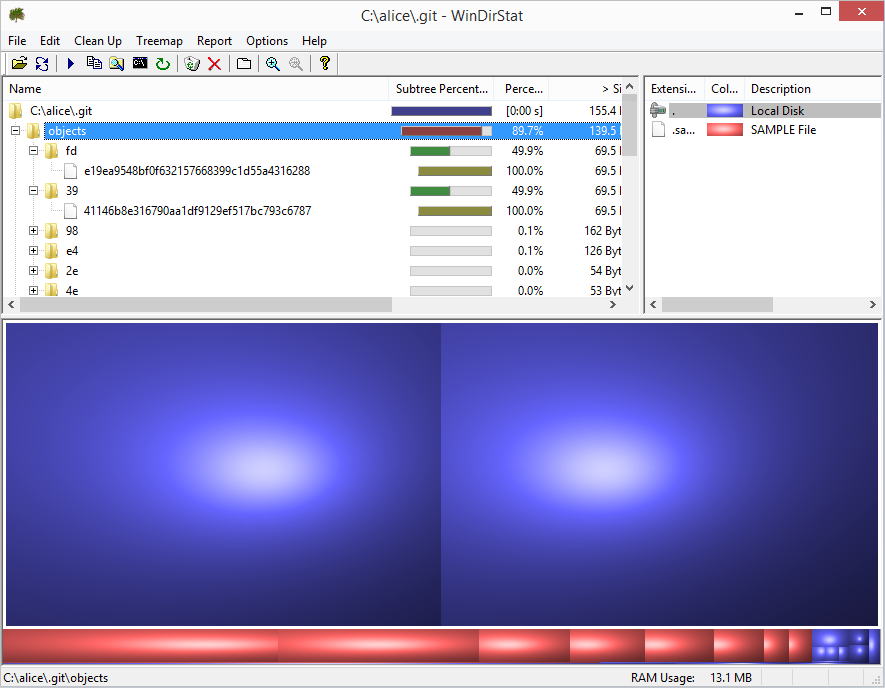
As you can see, Git stores two blobs of (nearly) identical size, one for each version of the text. If Git stored diffs, you’d expect to see one large blob, and a second much smaller blob (plus other objects for the tree etc.)
This isn’t exactly a scientific proof about Git’s behavior, but hopefully it illustrates it enough to get the point across. If you want a more detailed explanation about how Git stores data, you can watch the YouTube video above, or read the Git documentation.